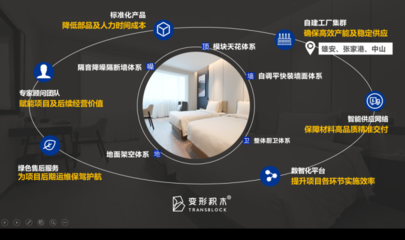
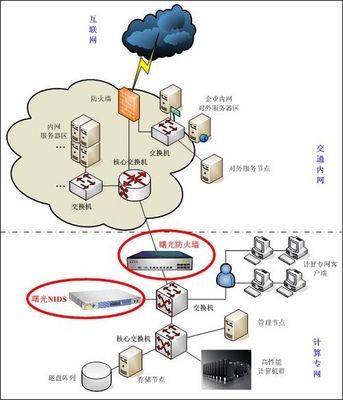
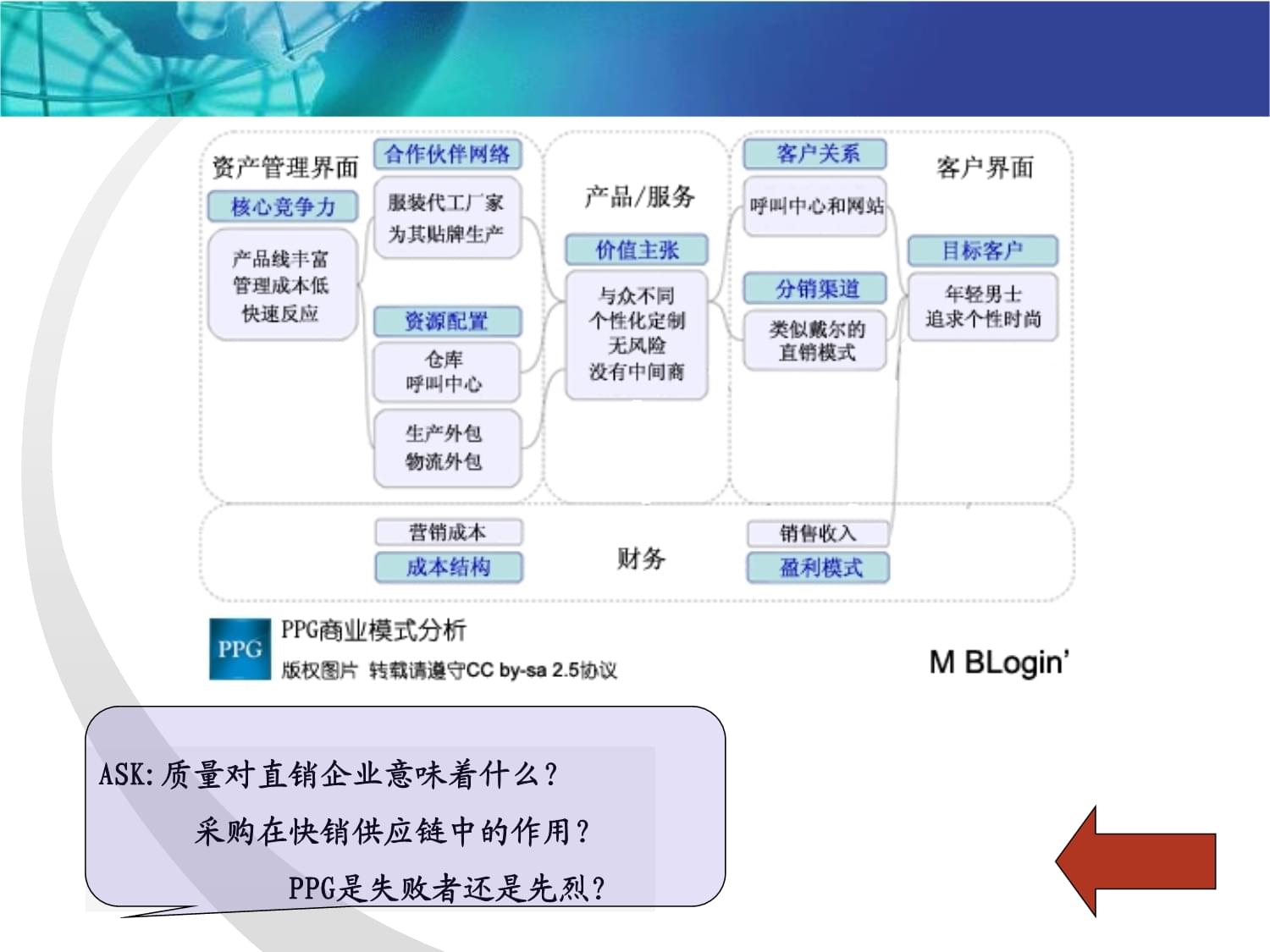
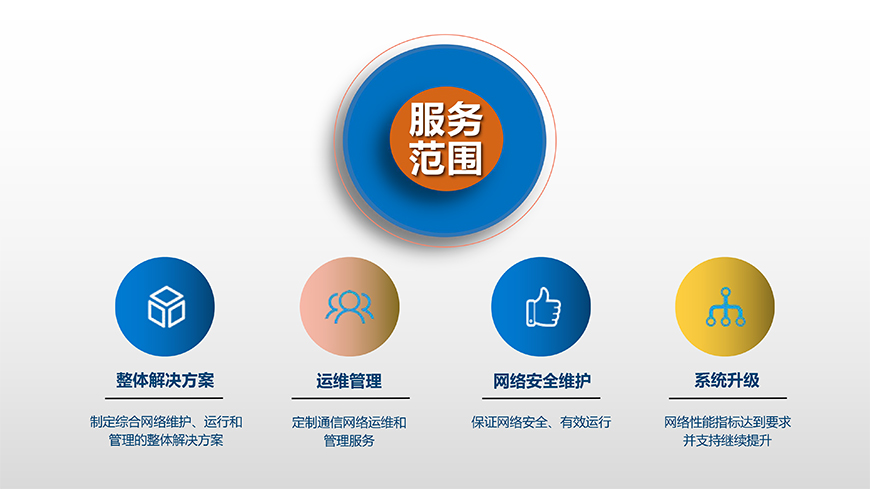
在數字化浪潮席卷全球的今天,網絡空間已成為企業競爭的主戰場。產品與服務的成功,越來越依賴于其在網絡世界中的可見度與影響力。“網絡推廣優化服務”正是企業應對這一挑戰、搶占市場先機的核心利器。其核心目標,是通過系統化、精準化的策略與執行,實現企業網絡信息的全面覆蓋,從而最大化產品曝光,驅動業務增長。
一、 全面覆蓋:構建多維網絡信息矩陣
網絡信息全面覆蓋,絕非簡單地在多個平臺注冊賬號。它意味著構建一個立體化、有機聯動的信息矩陣:
- 搜索引擎可見性(SEO): 通過關鍵詞優化、高質量內容建設、技術架構調整及權威外鏈獲取,使企業官網及核心內容在用戶搜索相關產品、服務或解決方案時,出現在搜索引擎結果頁的顯著位置。這是獲取精準流量、建立專業信任的基石。
- 社交媒體滲透: 根據目標用戶畫像,深耕微信、微博、抖音、小紅書、知乎、B站等主流社交平臺。通過賬號運營、內容營銷(圖文、短視頻、直播)、社群互動及KOL/KOC合作,在用戶日常瀏覽與社交場景中高頻次、個性化地傳遞品牌信息,建立情感連接。
- 權威平臺背書: 在行業垂直網站、新聞媒體、百科平臺、問答社區(如百度知道、知乎)等發布官方信息、專業文章、客戶案例或權威解答。這不僅直接覆蓋了有深度信息需求的用戶,更極大地提升了品牌的公信力與行業影響力。
- 付費廣告精準觸達(SEM/信息流): 利用搜索引擎廣告、社交媒體信息流廣告、聯盟廣告等付費渠道,基于大數據分析進行精準人群定向投放。能夠在短期內快速提升曝光,測試市場反應,并為自然流量運營積累數據。
二、 優化服務:以數據驅動精準曝光
“全面覆蓋”是廣度,“優化”則追求深度與效率。專業的網絡推廣優化服務,是一個持續循環的精細化管理過程:
- 策略定制與定位分析: 深入分析企業產品、目標市場、競爭對手及用戶行為,制定獨一無二的推廣組合策略。明確不同階段的曝光重點與核心信息。
- 內容創意與價值輸出: 曝光的基礎是吸引力。優化服務致力于創作符合各平臺調性、直擊用戶痛點、展現產品核心價值的優質內容。好內容自帶傳播屬性,是實現低成本、高轉化曝光的關鍵。
- 數據監測與效果評估: 利用各類分析工具,實時追蹤各渠道的曝光量、點擊率、訪問深度、轉化率等核心指標。用數據說話,清晰衡量每一分投入的回報。
- 持續迭代與動態調整: 根據數據反饋,快速識別高效渠道與優質內容形式,并果斷調整或優化效果不佳的環節。市場與用戶偏好瞬息萬變,推廣策略也必須具備高度的靈活性與敏捷性。
三、 引爆產品曝光:從“被看到”到“被記住”再到“被選擇”
當“全面覆蓋”的網絡信息矩陣與“持續優化”的專業服務相結合,便能產生強大的協同效應,實現產品曝光的層級躍遷:
- 初級曝光(被看到): 通過廣泛的渠道布局和內容分發,確保潛在客戶在多個網絡觸點都能接觸到產品信息,解決“不知道”的問題。
- 深度曝光(被記住): 通過持續、一致且有價值的內容輸出,以及積極的互動溝通,在用戶心中建立鮮明的品牌形象和產品認知,形成品牌記憶點,解決“不記得”的問題。
- 轉化曝光(被選擇): 當用戶產生需求時,由于前期的全面信息覆蓋和品牌建設,你的產品能第一時間被想起、被搜索、被比較,并最終憑借強大的網絡口碑和清晰的價值主張促成購買決策,解決“不選擇”的問題。
###
專業的網絡推廣優化服務,是一項集戰略規劃、內容創意、技術執行與數據分析于一體的系統工程。它不再局限于單點突破,而是致力于為企業構建一個全方位、多層次、高韌性的網絡信息生態。在這個生態中,每一次曝光都精準有效,每一次觸達都價值沉淀,最終將網絡信息的全面覆蓋,轉化為產品市場聲量的持續放大與銷售業績的堅實增長。選擇專業的網絡推廣優化服務,就是為企業鋪設一條在數字世界中持續獲取客戶、贏得競爭的“高速公路”。